Learning Robot Control from Simulated Experience
Training control policies in high-throughput differentiable simulators and deploying them directly on real robots.
This research studies how robots can acquire agile control behaviors from massive amounts of simulated experience — behaviors that would be too slow, too expensive, or too dangerous to learn through real-world trial and error.
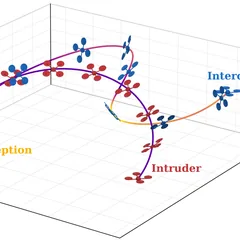
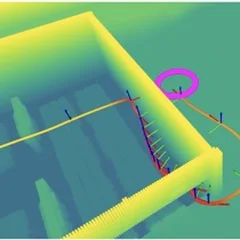
Real-world experience is a scarce resource for robot learning: crashes are costly, flight time is limited, and agile maneuvers put hardware at risk. Simulation removes these constraints. Our work trains control policies end-to-end in high-throughput differentiable simulators, where millions of trials cost nothing and the simulator’s full state is open to inspection. We exploit that transparency through privileged information — time-of-arrival maps for navigation, intruder states for interception — which shapes the training loss but is never available at inference, so the deployed policies rely only on onboard sensing. Differentiable quadrotor dynamics let us compute analytical policy gradients directly through the simulation, yielding better sample efficiency and smoother control than model-free alternatives. Crucially, the learned behaviors survive the transfer out of simulation: our navigation policy has flown hundreds of meters through forests and obstacle arenas, day and night, at speeds up to 4 m/s, using only what the robot can sense onboard.