This page is kept for archival purposes only. The actual project webpage is at rislab.org/projects/catchrl.html.
Learning Agile Intruder Interception using Differentiable Quadrotor Dynamics
arXiv · 2026
How can a quadrotor intercept an agile intruder using only a monocular direction measurement, without knowing the intruder's position or distance?
This paper presents a methodology for learning a control policy to intercept an intruder using the 3D direction unit vector to the intruder and the interceptor state. Prior deep reinforcement learning approaches assume either relative position or distance to the intruder is available, but this information is not readily accessible in real-world applications that employ passive, monocular camera sensors. Instead, we propose a solution that leverages an analytical policy gradient method using differentiable quadrotor dynamics to learn agile interception at speeds up to 10 m/s. The proposed approach outperforms baseline methods that utilize simplified point mass dynamics by an average of 30%.
Figures
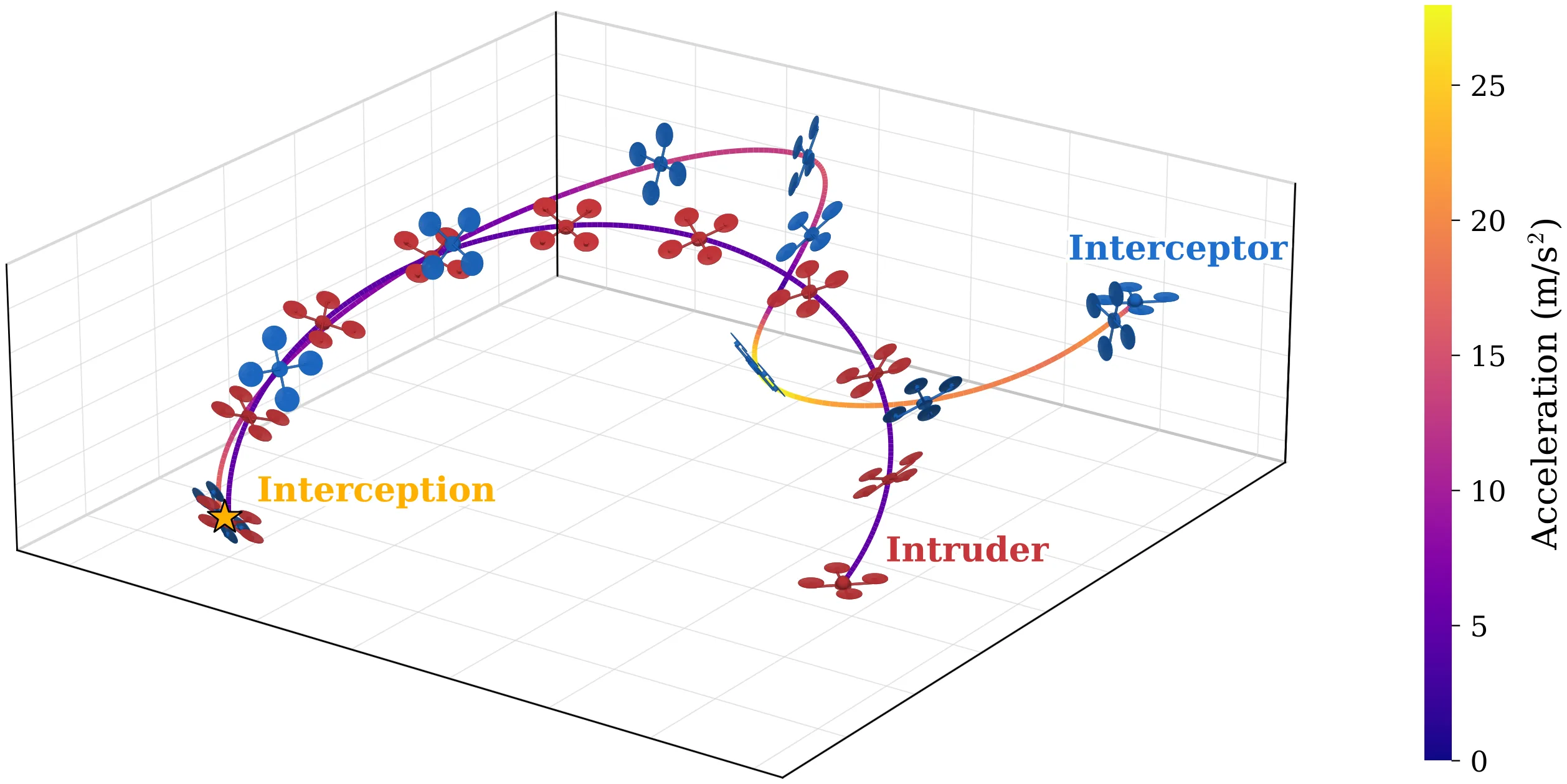
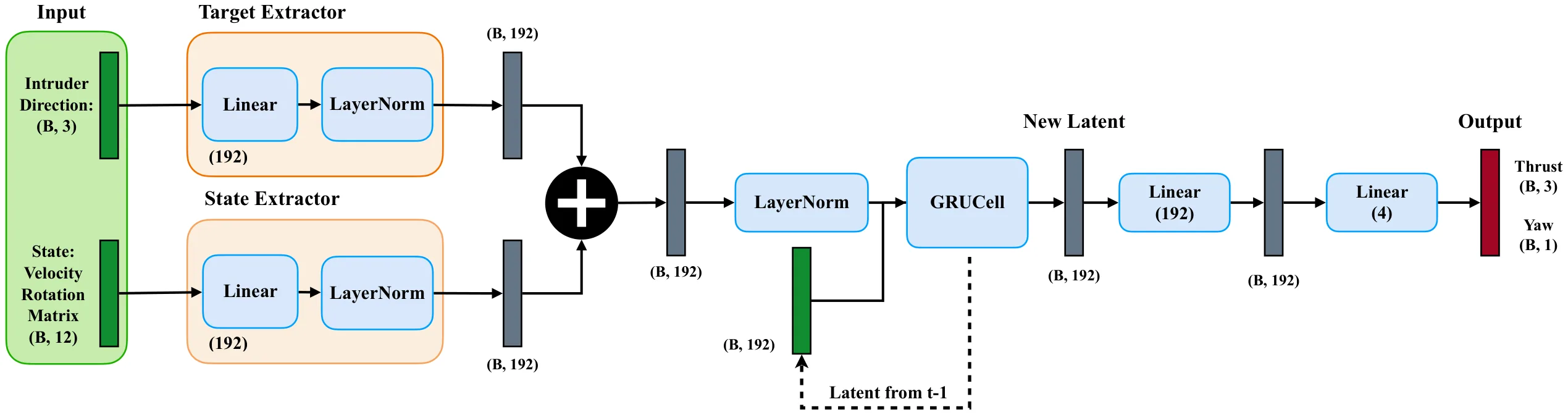
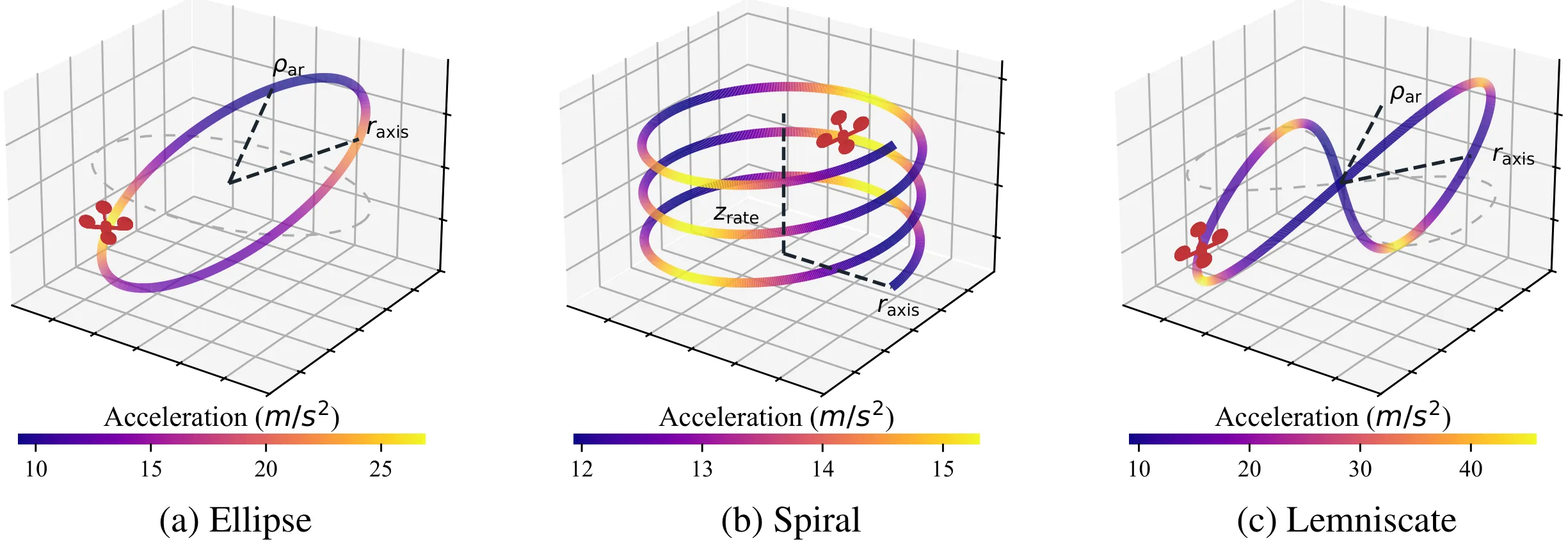
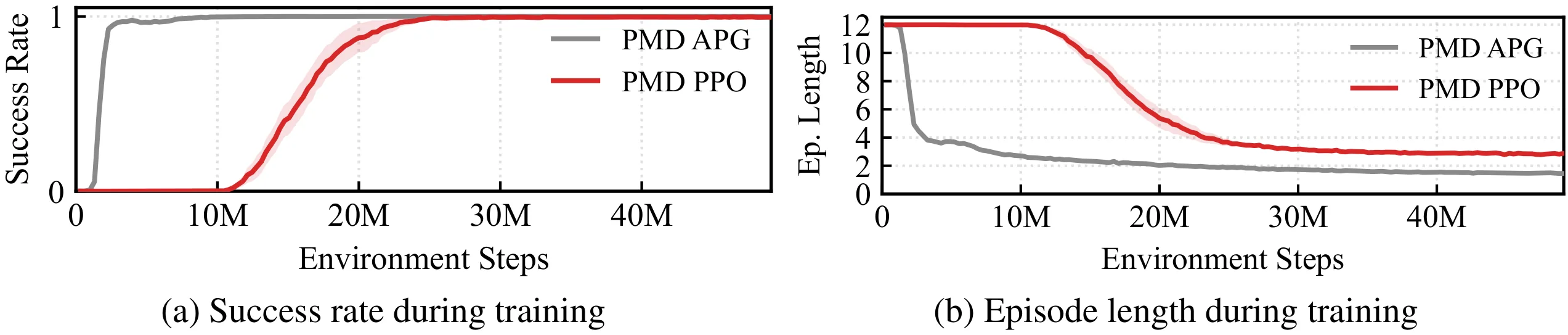
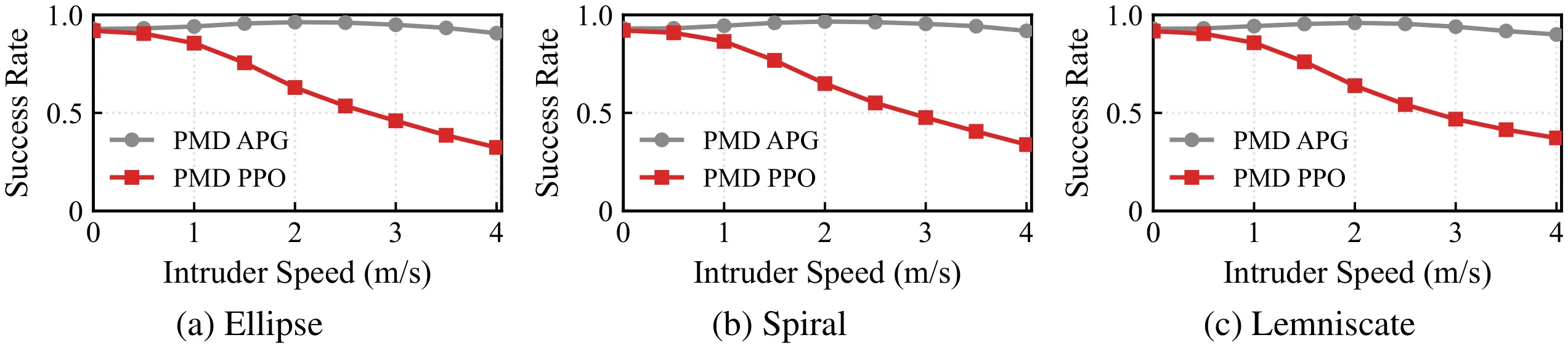
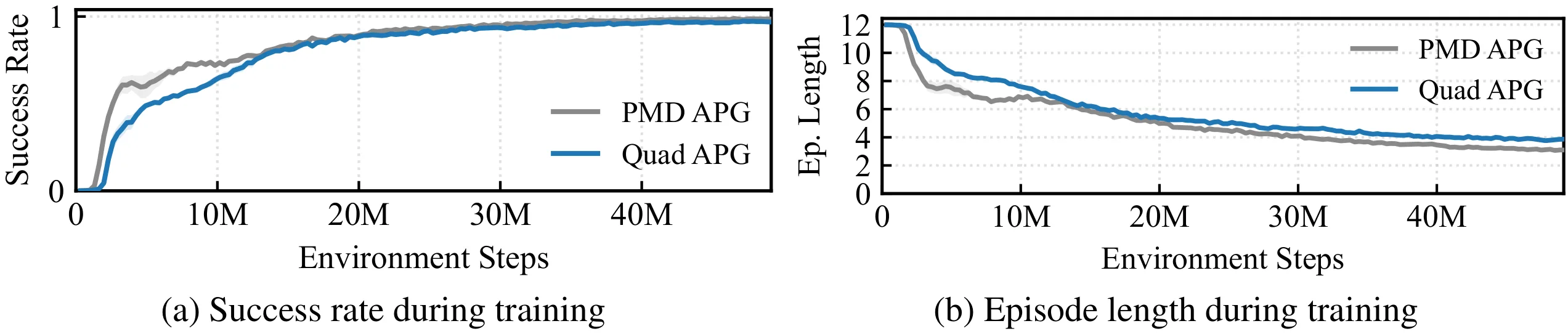
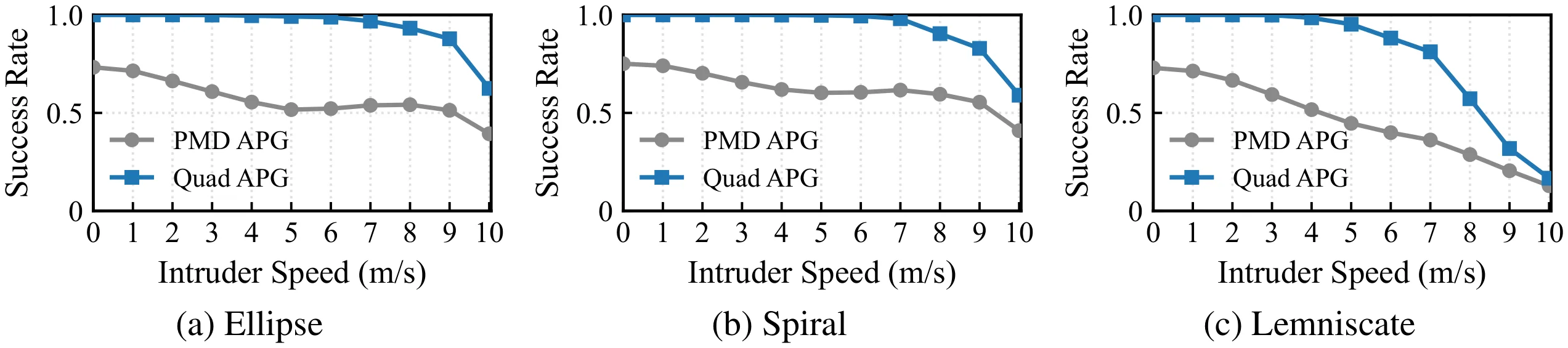
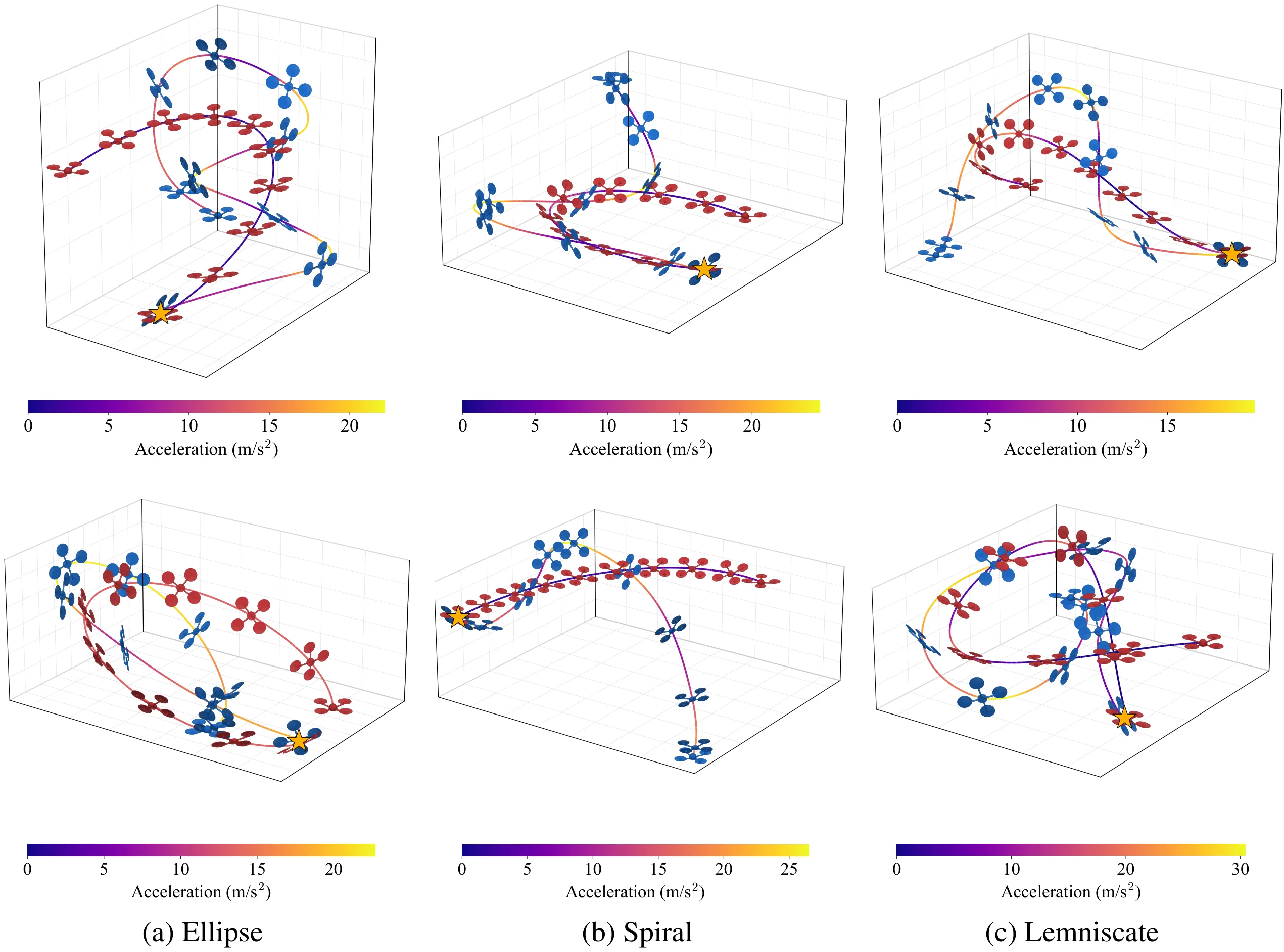
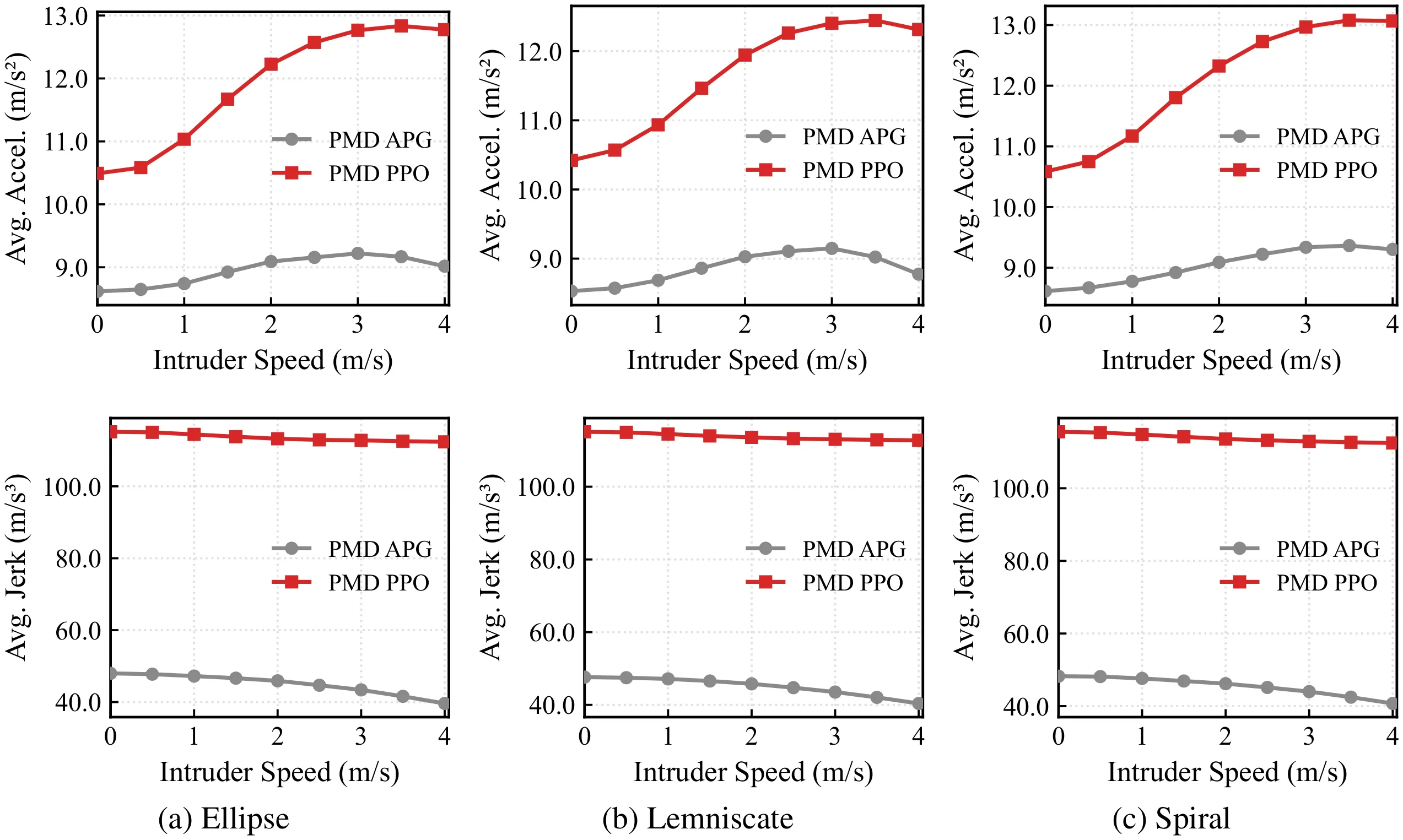
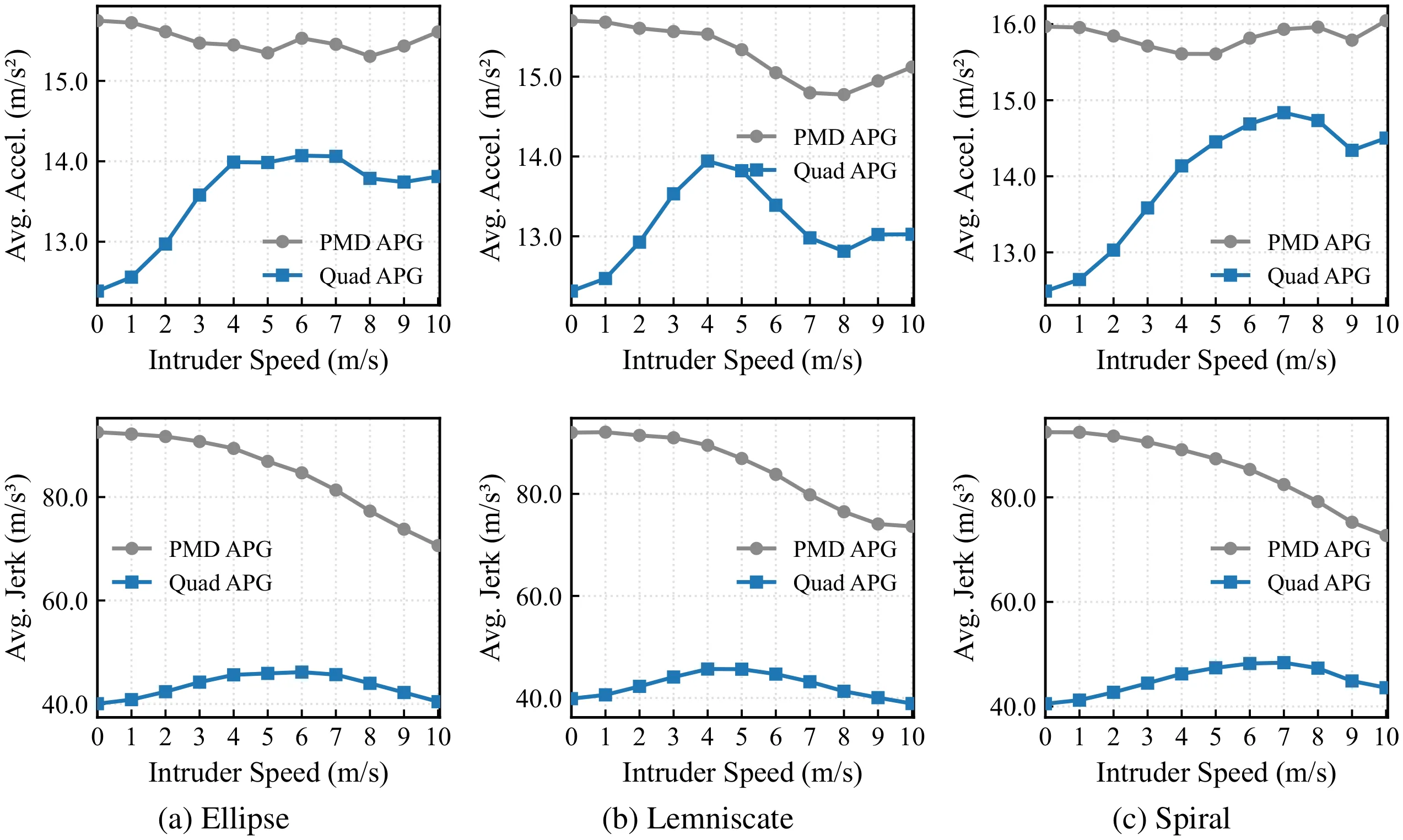
The training objective decomposes classical parallel-navigation guidance into two terms: a line-of-sight alignment loss that forces the relative velocity to point along the line of sight, and a closing-velocity loss that drives the interceptor to aggressively close the gap. Intruder state details are privileged — used only inside the loss during training and never at inference, where the policy sees only its own state and the 3D unit direction to the intruder. A GRU-based policy network implicitly estimates the target’s velocity and acceleration from temporal sequences of unit directions, and outputs mass-normalized thrust and yaw commands executed by an onboard PD attitude controller. The learned policy generalizes from ellipse training trajectories to out-of-distribution spiral and lemniscate targets.
Acknowledgments
This research was supported in part by an AI2C Seed grant and the NVIDIA Academic Grant Program.
BibTeX
@article{intruder-interception-2026,
title={Learning Agile Intruder Interception using Differentiable Quadrotor Dynamics},
author={Michael Anoruo, Xiaoyu Tian, Abhishek Rathod, Timothy Naudet, Thomas Canchola, Eric Sturzinger, Kshitij Goel, and Wennie Tabib},
journal={arXiv preprint arXiv:2607.02472},
year={2026}
}