Quadrotor Navigation using Reinforcement Learning with Privileged Information
ICRA · 2026
How to reduce the failures that conventional modular pipelines for quadrotor navigation cause using an end-to-end deep learning approach?
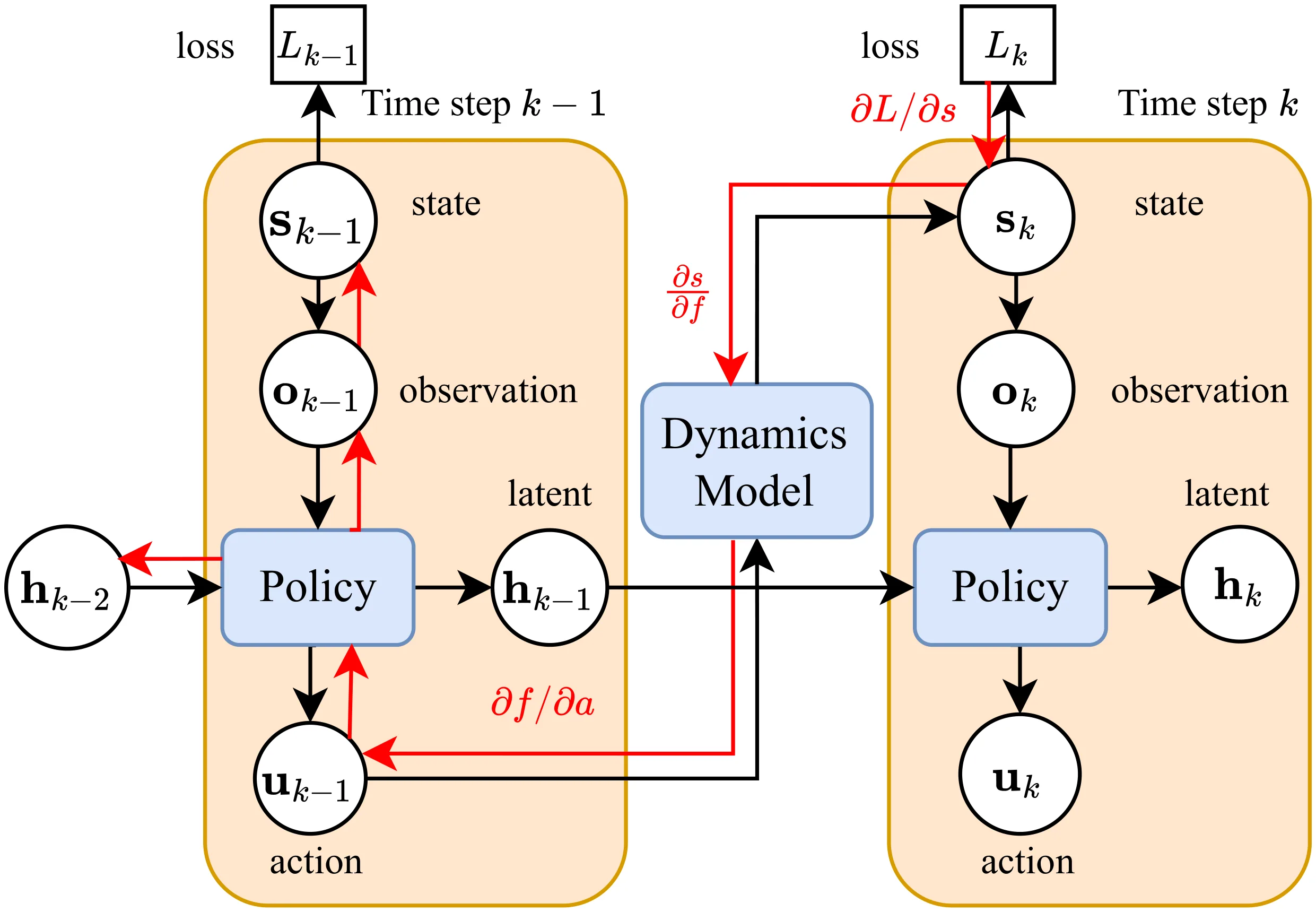
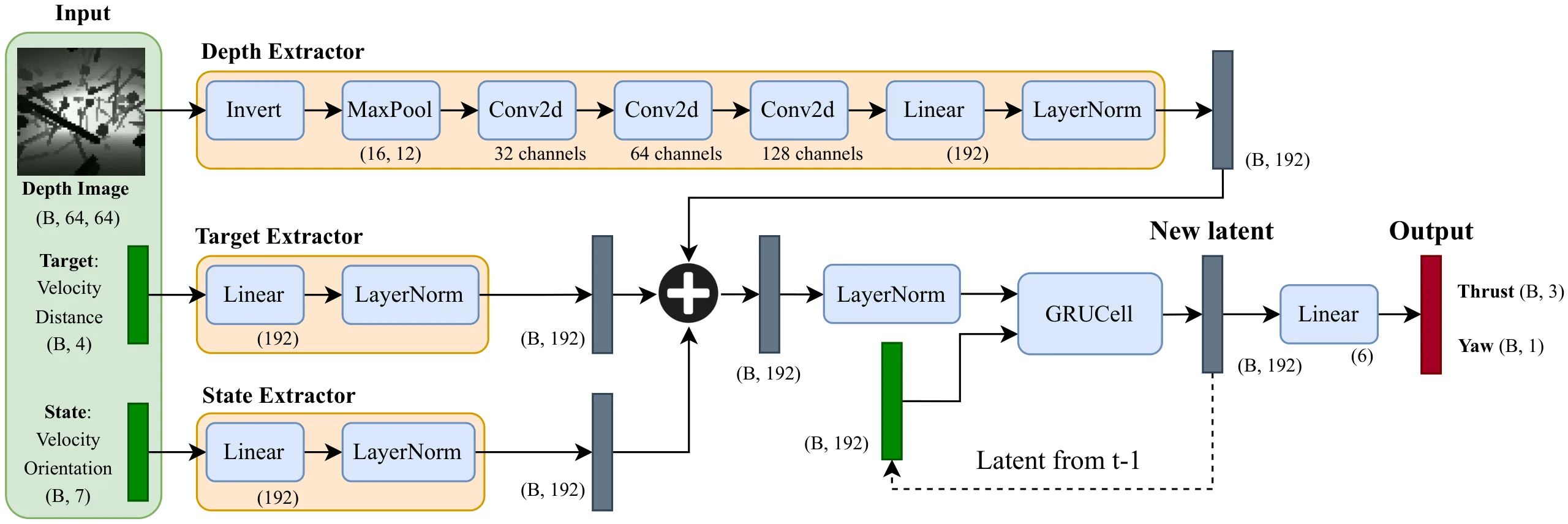
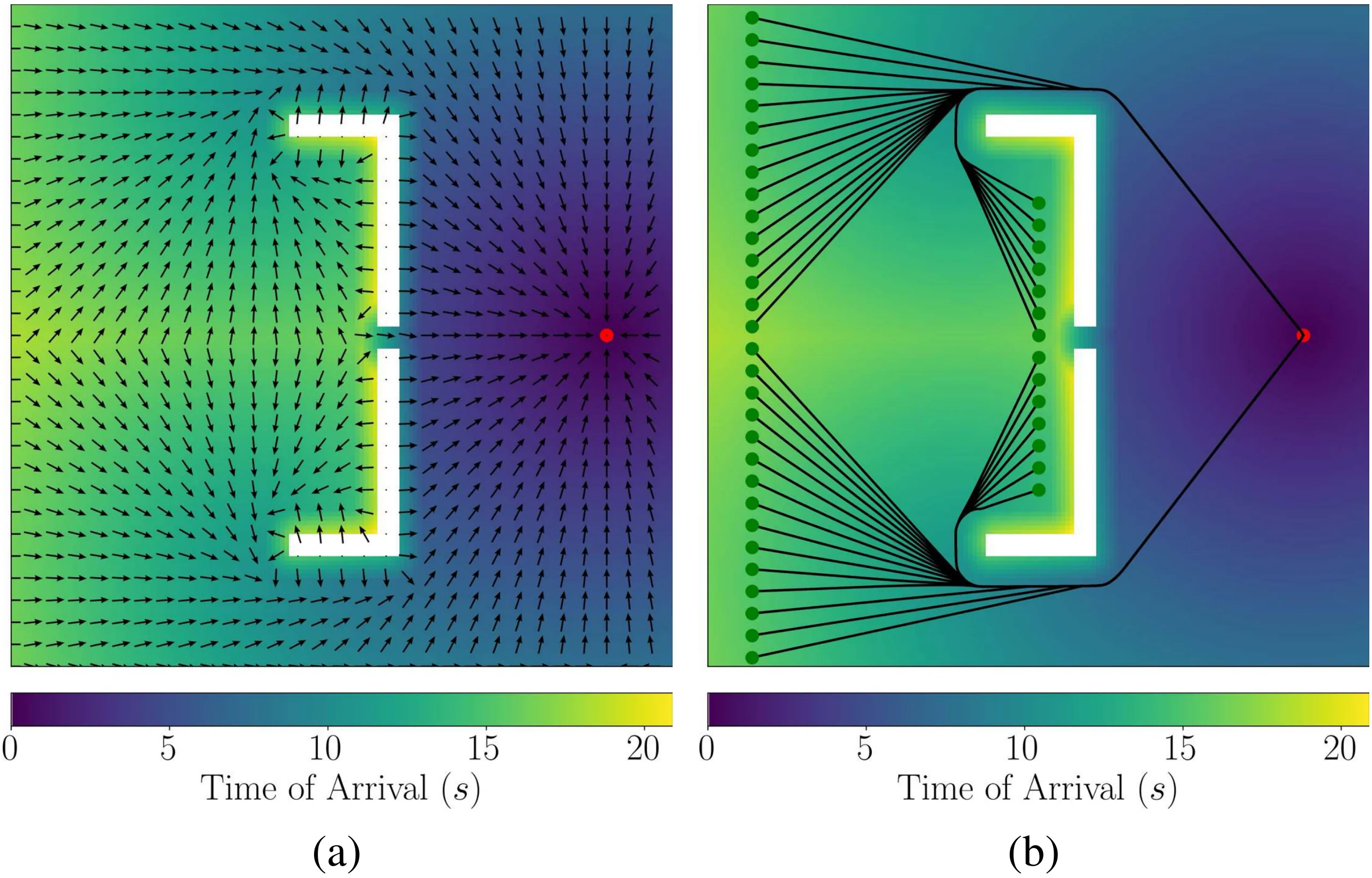
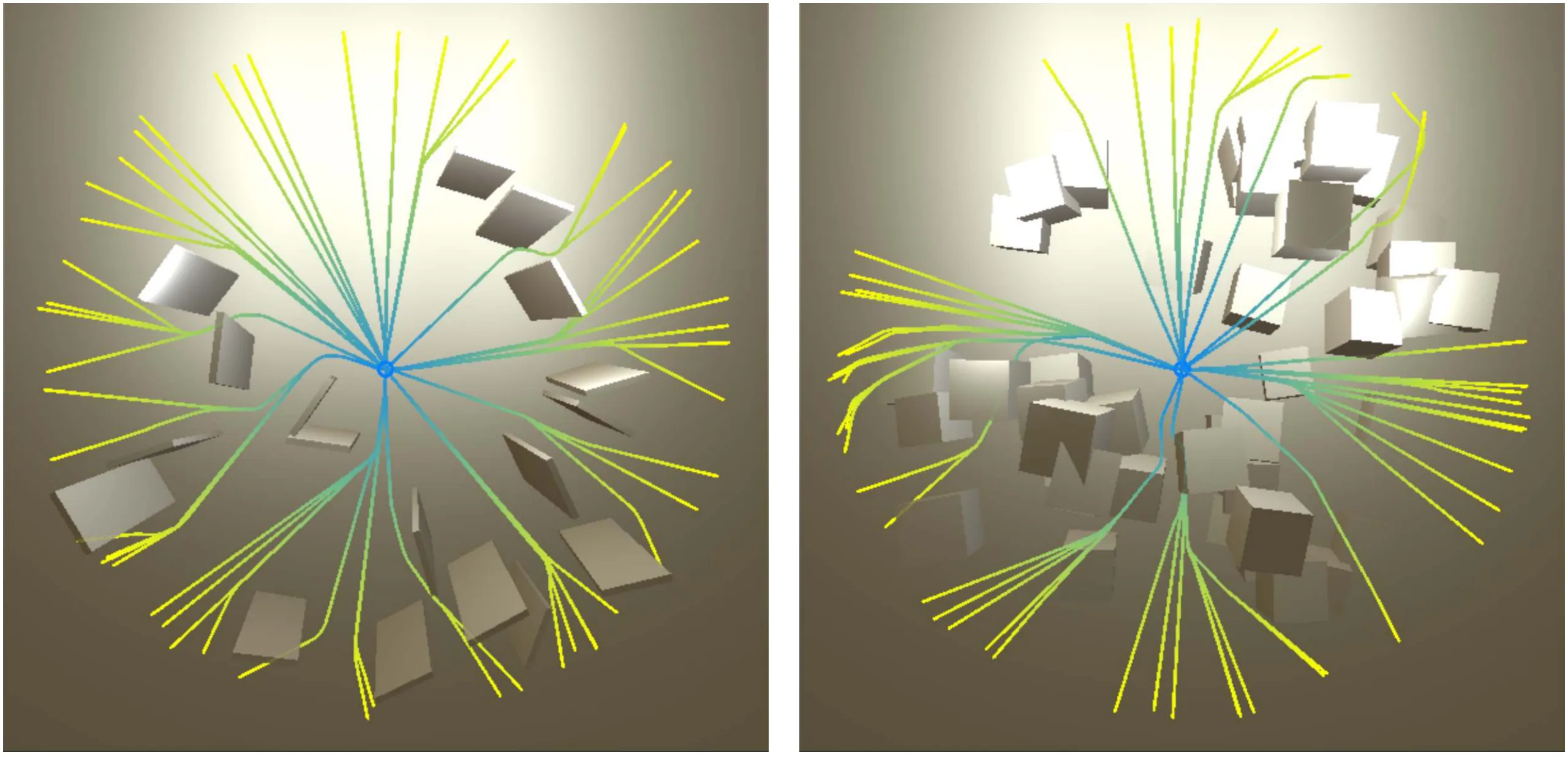
This paper presents a reinforcement learning-based quadrotor navigation method that leverages efficient differentiable simulation, novel loss functions, and privileged information to navigate around large obstacles. Prior learning-based methods perform well in scenes that exhibit narrow obstacles, but struggle when the goal location is blocked by large walls or terrain. In contrast, the proposed method utilizes time-of-arrival (ToA) maps as privileged information and a yaw alignment loss to guide the robot around large obstacles. The policy is evaluated in photo-realistic simulation environments containing large obstacles, sharp corners, and dead-ends. Our approach achieves an 86% success rate and outperforms baseline strategies by 34%. We deploy the policy onboard a custom quadrotor in outdoor cluttered environments both during the day and night. The policy is validated across 20 flights, covering 589 meters without collisions at speeds up to 4 m/s.
Figures

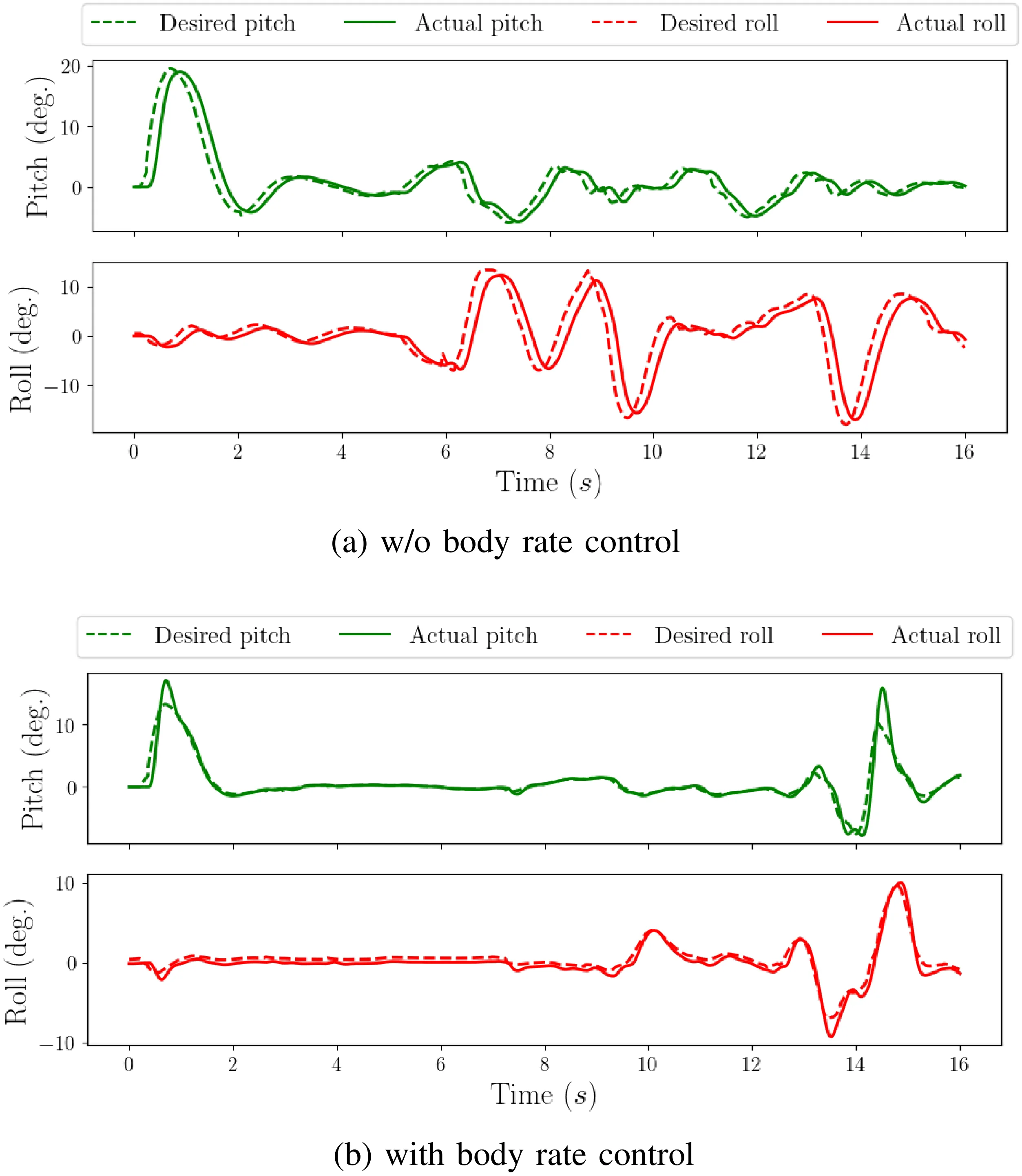
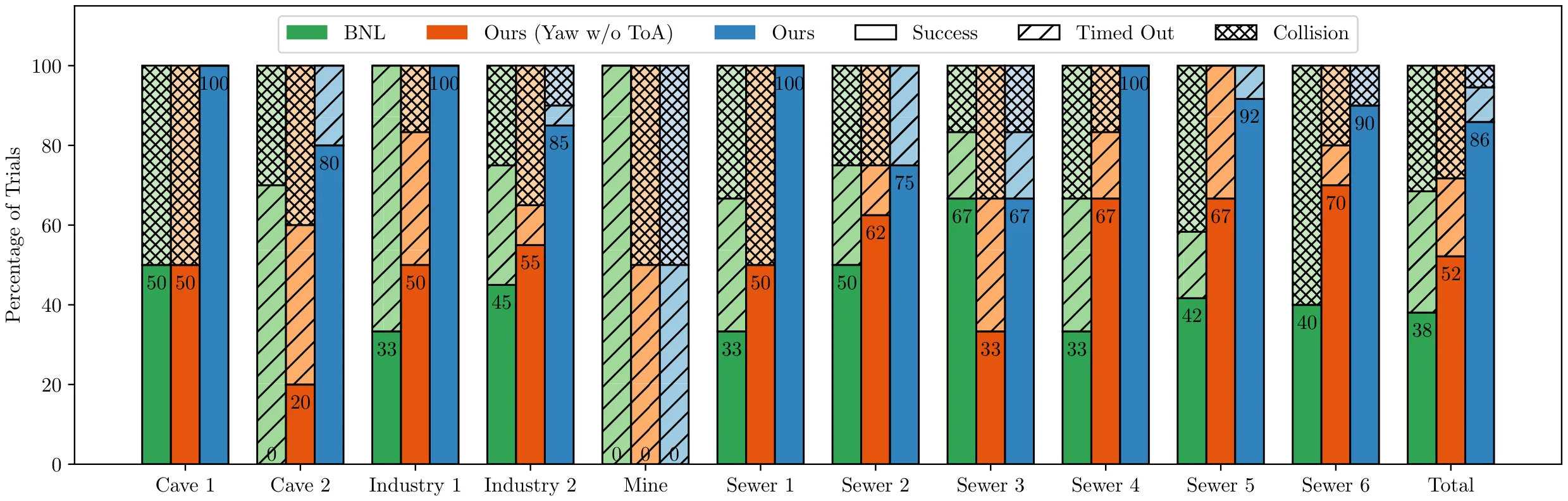
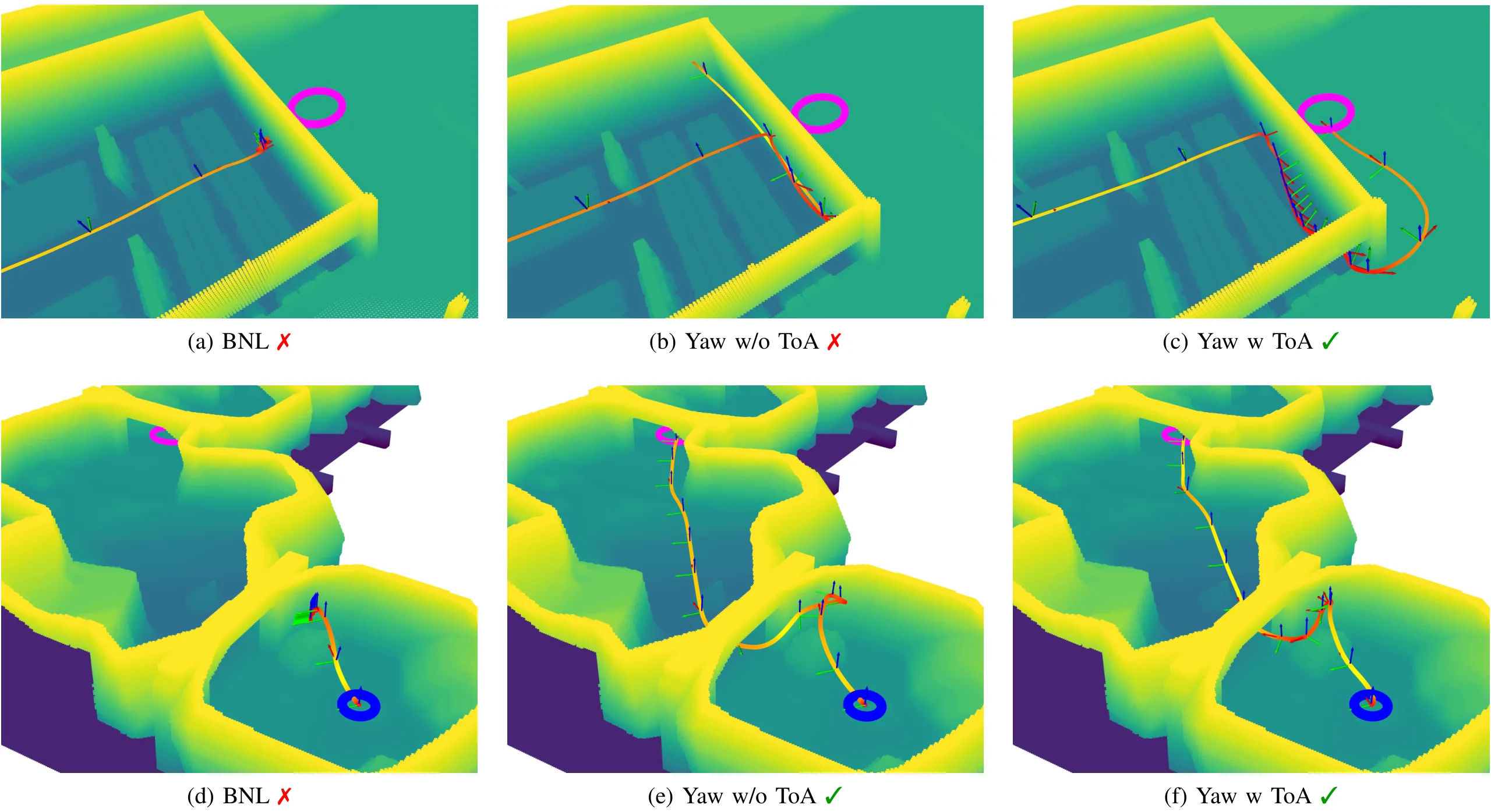
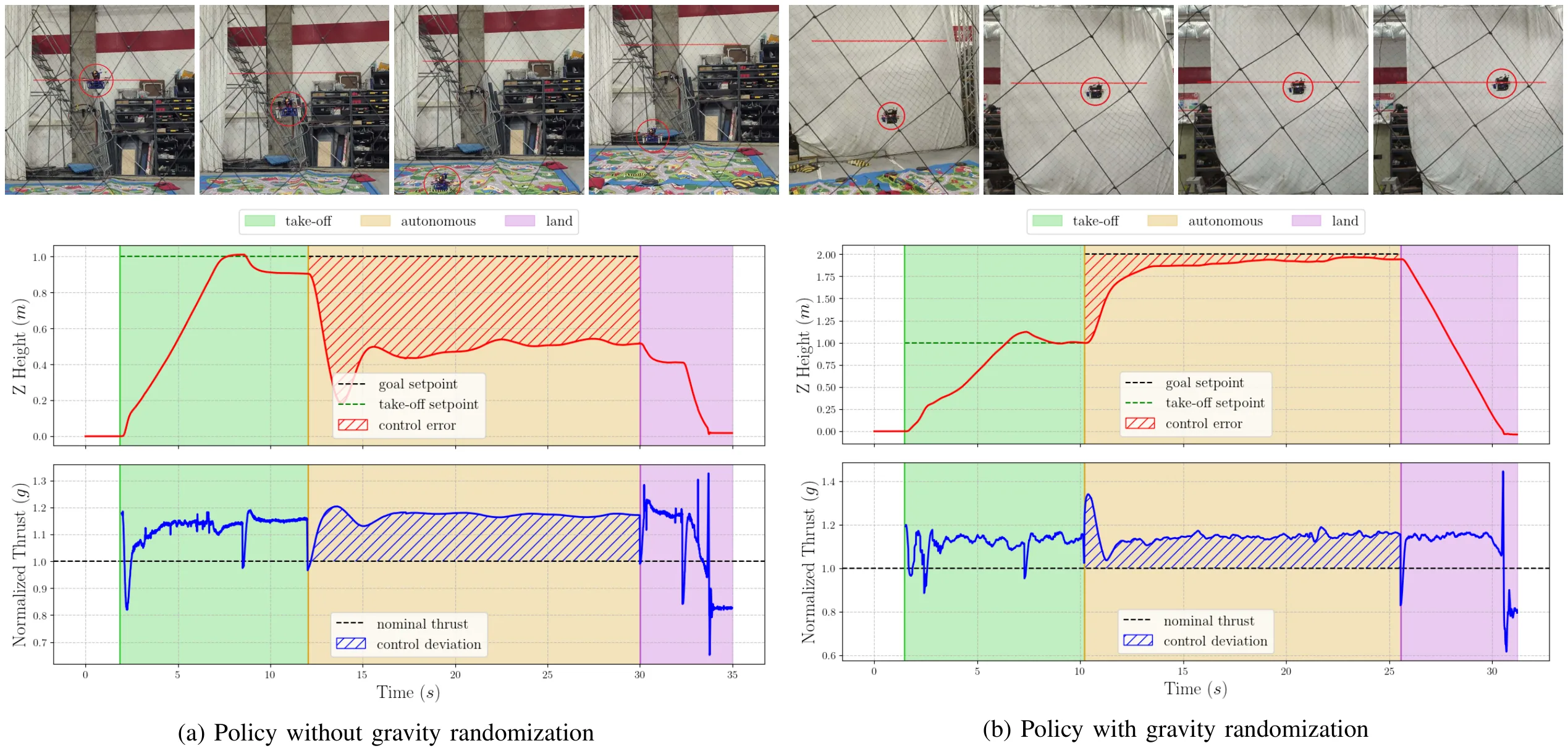
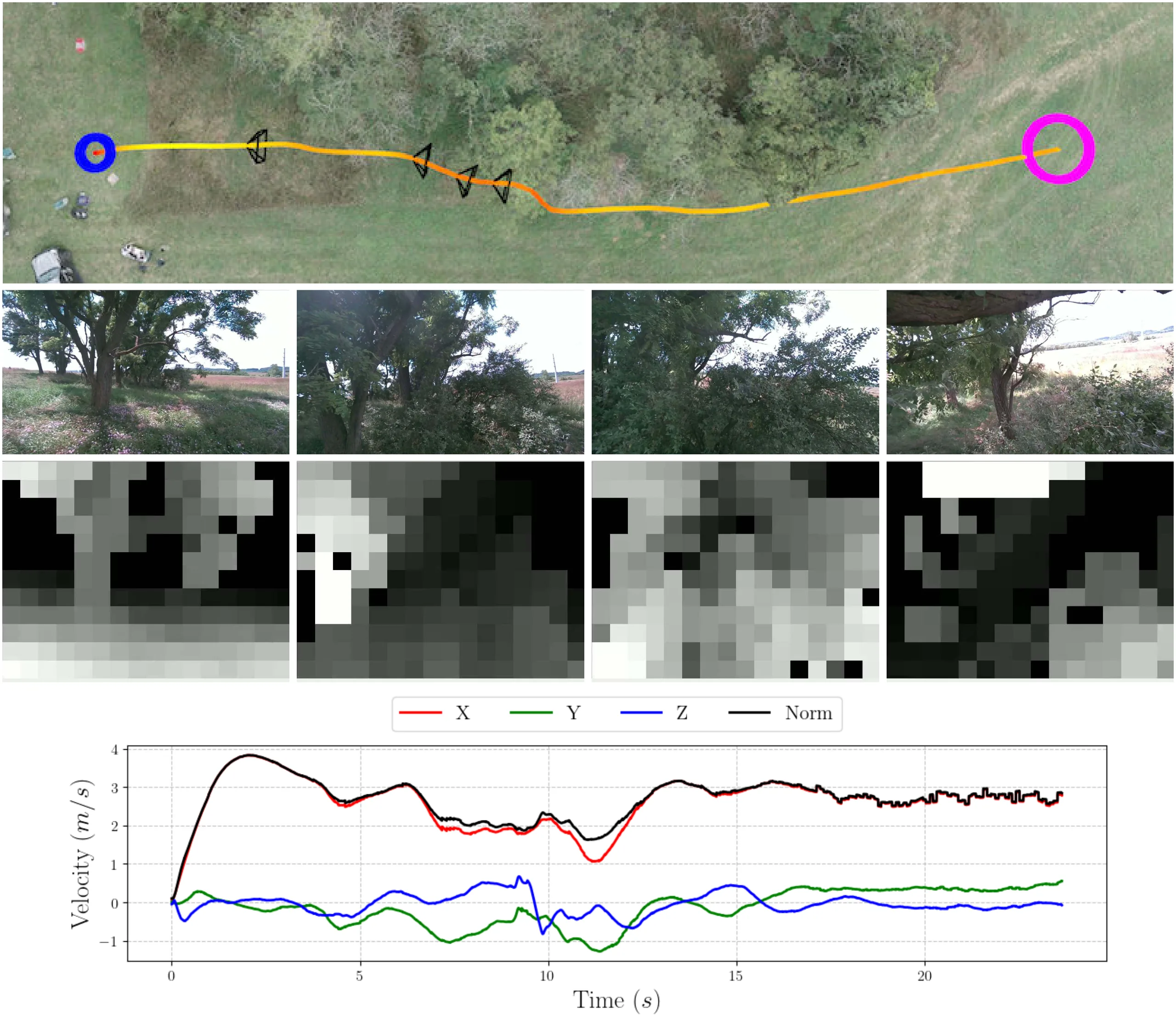
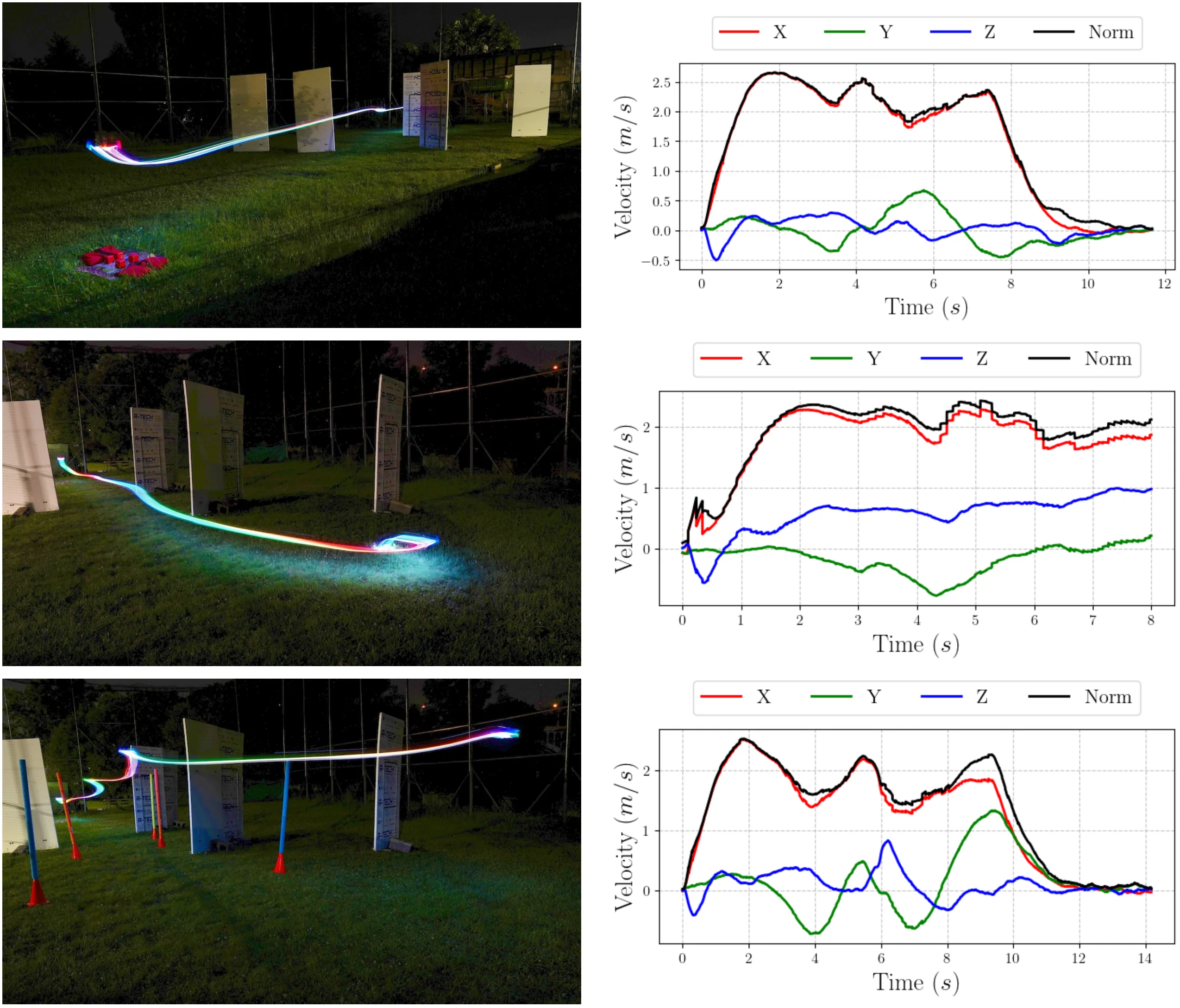
Acknowledgments
The authors would like to thank Ankit Khandelwal for contributions to the codebase and Edsel Burkholder for field testing support. This material is based upon work supported in part by the Army Research Laboratory and the Army Research Office under contract/grant number W911NF-25-2-0153.
BibTeX
@inproceedings{quadrotor-navigation-rl-2026,
title={Quadrotor Navigation using Reinforcement Learning with Privileged Information},
author={Jonathan Lee, Abhishek Rathod, Kshitij Goel, John Stecklein, and Wennie Tabib},
booktitle={IEEE International Conference on Robotics and Automation (ICRA), 2026},
year={2026}
}